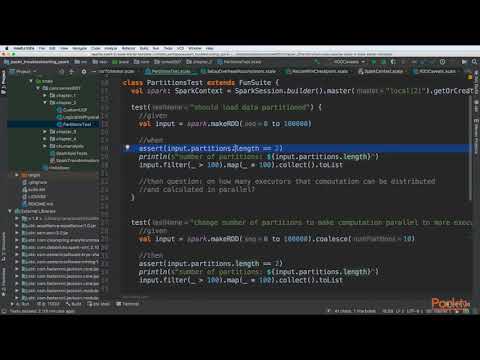
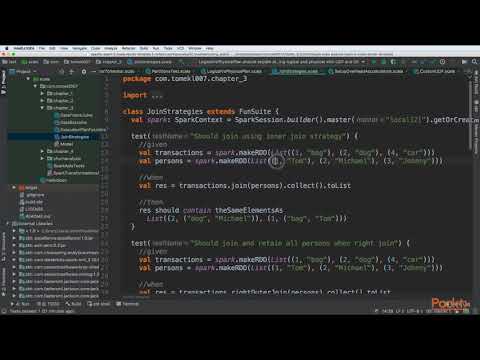
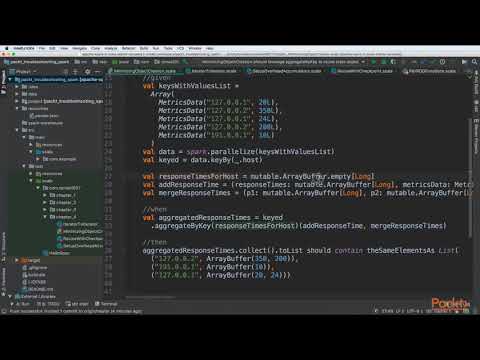
Lessons no : 5
For Free Certificate After Complete The Course
To Register in Course you have to watch at least 30 Second of any lesson
Join The Course Go To Community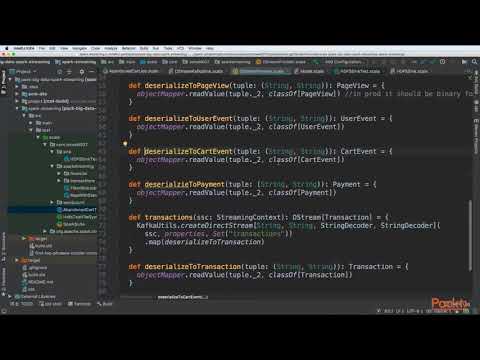
Be the First One Review This Course
Our New Certified Courses Will Reach You in Our Telegram Channel
Join Our Telegram Channels to Get Best Free Courses